数据库存储引擎 数据处理与存储服务的核心
在当今数据驱动的时代,数据库存储引擎作为数据处理和存储服务的核心组件,其性能、可靠性和功能直接影响着整个应用系统的表现。本文将探讨数据库存储引擎的基本概念、主要类型及其在数据处理与存储服务中的关键作用。
一、数据库存储引擎概述
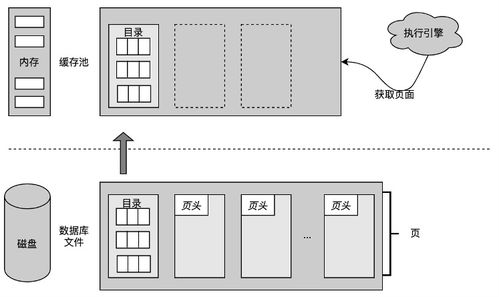
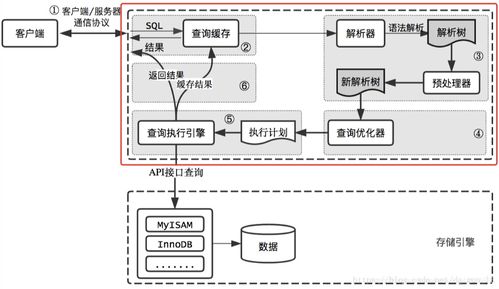
数据库存储引擎(Storage Engine),也称为数据库引擎,是数据库管理系统(DBMS)中负责数据的存储、检索、更新和删除操作的底层软件组件。它位于数据库系统的底层,直接与操作系统和硬件交互,负责将逻辑上的数据模型(如表、行、列)映射到物理存储介质(如硬盘、SSD)上。可以说,存储引擎是数据库的“心脏”,决定了数据如何被组织、访问和持久化。
二、主流存储引擎类型及其特点
不同的存储引擎采用不同的数据结构和算法,以适应不同的应用场景。以下是几种常见的存储引擎类型:
- InnoDB(MySQL):
- 特点:支持事务处理(ACID特性)、行级锁、外键约束,并提供崩溃恢复能力。
- 适用场景:适用于需要高并发、事务安全性的OLTP(在线事务处理)应用,如电商、金融系统。
- MyISAM(MySQL):
- 特点:不支持事务和行级锁(表级锁),但读取速度较快,支持全文索引。
- 适用场景:适用于读多写少、不需要事务支持的场景,如数据仓库、内容管理系统(CMS)的读操作。
- RocksDB(嵌入式/分布式系统):
- 特点:基于LSM-Tree(日志结构合并树)的键值存储引擎,写性能极高,支持高吞吐量的数据写入。
- 适用场景:广泛应用于分布式数据库(如TiDB、CockroachDB)、消息队列和需要高性能写入的嵌入式系统中。
- WiredTiger(MongoDB):
- 特点:支持文档级别的并发控制、压缩和缓存,旨在提供高性能的读写操作。
- 适用场景:作为MongoDB的默认存储引擎,适用于灵活的文档型数据存储和处理。
- LevelDB(Google):
- 特点:同样是基于LSM-Tree的轻量级键值存储库,提供快速的读写操作。
- 适用场景:常用于浏览器存储、缓存系统以及其他需要高效本地存储的应用。
三、存储引擎在数据处理与存储服务中的关键作用
- 性能决定者:存储引擎的设计直接决定了数据库的读写速度、并发处理能力和响应延迟。例如,LSM-Tree引擎优化了写入性能,而B+Tree引擎则在读写均衡和范围查询上表现优异。
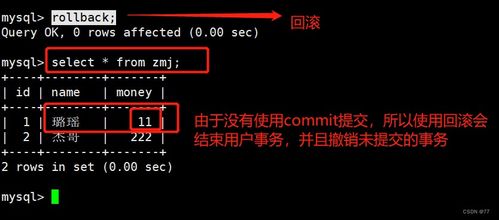
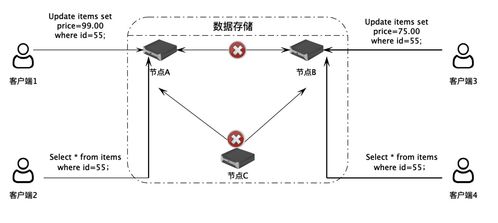
- 数据一致性与可靠性保障:对于关键业务系统,存储引擎通过实现WAL(Write-Ahead Logging,预写式日志)、事务支持和崩溃恢复机制,确保数据的持久性和一致性,即使在系统故障时也能恢复数据。
- 支持多样化的数据模型:不同的存储引擎支持不同的数据组织方式,如关系型、文档型、键值型等,这使数据库能够灵活适应各种数据处理需求。
- 资源管理与优化:存储引擎负责管理内存缓存(如Buffer Pool)、磁盘I/O、数据压缩和索引维护,通过优化这些资源的利用来提升整体效率并降低成本。
- 可扩展性与灵活性基础:在现代分布式数据库和云存储服务中,存储引擎的可插拔设计允许根据工作负载动态选择或切换引擎,为实现水平扩展和混合负载处理提供了基础。
四、选择存储引擎的考量因素
在选择或评估存储引擎时,应考虑以下关键因素:
- 工作负载模式:是读密集型、写密集型还是混合型?是否需要高并发事务?
- 数据一致性要求:是否需要严格的ACID事务支持?还是可以接受最终一致性?
- 性能目标:更关注延迟、吞吐量还是两者兼顾?
- 硬件环境:使用的是HDD、SSD还是内存?存储引擎能否充分利用硬件特性?
- 功能需求:是否需要全文搜索、地理空间支持或特定的索引类型?
五、
数据库存储引擎远不止是简单的数据“存放处”,它是数据处理和存储服务的智能核心。从传统的磁盘管理到如今面向云原生和分布式场景的优化,存储引擎的持续演进正推动着数据库技术不断突破性能、可靠性和灵活性的边界。理解不同存储引擎的原理与特性,对于设计高效、可靠的数据密集型应用至关重要。无论是开发人员、架构师还是运维工程师,掌握存储引擎的相关知识,都将有助于在复杂的技术选型与系统优化中做出更明智的决策。
(注:本文参考了包括CSDN博客用户“weixin_44604586”在内的广大技术社区分享的知识与经验,在此对开源技术社区的贡献表示感谢。)
如若转载,请注明出处:http://www.lookmq.com/product/85.html
更新时间:2026-06-19 11:04:00