从0开始学大数据06 新技术层出不穷,HDFS依然是存储的王者
引言
在大数据技术日新月异的今天,各种新型的存储和处理框架层出不穷,例如云原生存储、对象存储、实时数据库等。当我们深入大数据生态系统的核心时,会发现Hadoop分布式文件系统(HDFS)依然稳坐“存储王者”的宝座。为什么在新技术浪潮中,HDFS能保持其不可撼动的地位?本文将带你从数据处理和存储服务的角度,一探究竟。
HDFS的核心优势
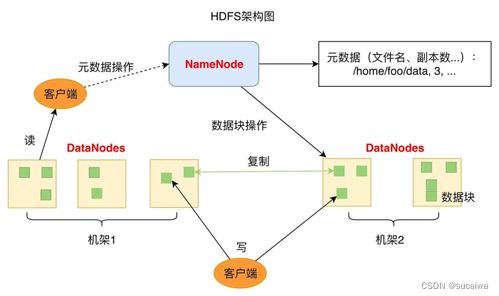
- 高容错性与可靠性:HDFS通过数据块的多副本机制(默认3副本),确保即使某个节点发生故障,数据也不会丢失。这种设计特别适合大规模集群环境,保障了数据存储的持久性。
- 高吞吐量访问:HDFS针对一次写入、多次读取的场景优化,能够高效处理海量数据的批处理任务。例如,在MapReduce、Spark等计算框架中,HDFS能提供稳定的数据支持。
- 成本效益:HDFS可以部署在廉价的商用硬件上,通过横向扩展来增加存储容量,避免了传统存储系统的高昂成本。
- 成熟的生态系统:作为Hadoop生态的基石,HDFS与众多大数据工具(如Hive、HBase、Flink)无缝集成,形成了完整的数据处理链条。
新技术浪潮下的挑战与机遇
尽管云存储(如AWS S3、Azure Blob Storage)和实时数据库(如Kafka、Cassandra)在大数据领域崭露头角,但它们往往与HDFS形成互补而非替代关系:
- 云存储:适合冷数据备份或跨区域共享,但实时计算性能可能不及HDFS。
- 实时数据库:擅长流处理,但缺乏HDFS的海量存储能力。
HDFS通过持续演进(如支持纠删码以降低存储开销、优化小文件处理)来应对新需求,同时其“数据本地化”特性(将计算任务调度到数据所在节点)仍是提升效率的关键。
数据处理与存储服务的实践场景
在实际应用中,HDFS常作为数据湖的核心存储层:
1. 数据采集与存储:将日志、交易数据等原始信息批量写入HDFS,形成可追溯的数据基础。
2. 批量处理:通过MapReduce或Spark对HDFS中的数据进行ETL(提取、转换、加载),生成结构化数据集。
3. 混合架构:结合Kafka处理实时流数据,并将结果持久化到HDFS,实现批流一体的数据处理。
例如,某电商平台使用HDFS存储历史订单数据,通过Spark进行用户行为分析,同时用S3备份非活跃数据,形成高效且经济的存储体系。
未来展望
随着AI和物联网的兴起,数据量呈现爆炸式增长。HDFS的演进方向可能包括:
- 更好地融合云原生技术,支持弹性伸缩。
- 增强对非结构化数据(如图像、视频)的管理能力。
- 优化与内存计算、GPU加速等新硬件的协作。
但无论如何,其核心设计理念——可靠、可扩展、低成本——将继续为大数据存储奠定基石。
###
大数据的世界虽不断有新星闪耀,但HDFS凭借其经久考验的架构和生态优势,依然是存储领域的“定海神针”。对于学习者而言,深入理解HDFS的原理与应用,不仅是掌握大数据技术的必经之路,更是应对未来技术变革的坚实基础。在下一讲中,我们将探索如何基于HDFS构建数据处理管道,敬请期待!
如若转载,请注明出处:http://www.lookmq.com/product/79.html
更新时间:2026-06-19 10:37:38