智能推荐时代的信息过载 从数据与存储层入手
在数字信息爆炸的今天,智能推荐系统已成为我们获取内容的主要门户,无论是新闻阅读、视频观看还是商品选购。正是这些旨在提升效率的推荐算法,有时却加剧了『信息过载』——用户在海量、重复或低质的内容推送中感到疲惫与迷失。要根治这一顽疾,我们不应仅着眼于算法模型的优化,更需溯本清源,从底层的数据处理与存储服务入手,构建更健康、高效的信息生态。
一、 数据之源:质量、维度与时效性的三重奏
信息过载的本质,往往是『数据过载』但『信息不足』。推荐系统依赖的数据若存在偏差、噪声或片面性,无论算法多么精巧,输出都可能加剧用户的认知负担。
- 提升数据质量与标注精度:原始数据中的错误、重复和垃圾信息是推荐噪音的主要来源。在数据摄入层,必须建立强大的清洗、去重和验证管道。尤其是在监督学习场景下,标注数据的质量直接决定模型的上限。引入更科学的人工标注流程、利用半自动化工具辅助,甚至探索基于用户隐式反馈的自动校准,都能为算法提供更纯净的『食材』。
- 拓展数据维度,突破『过滤气泡』:当前推荐系统多依赖于用户的历史行为数据(点击、观看、购买),这极易导致推荐范围越来越窄,形成信息茧房。解决之道在于引入更丰富、更多元的上下文数据维度。例如,结合用户的实时场景(位置、时间、设备)、社交图谱信息,以及内容本身的深层语义特征(通过NLP、CV技术提取)。在存储设计上,需要支持这些多模态、异构数据的灵活关联与高效查询,为算法提供更全面的用户与内容画像。
- 保障数据的时效性与动态性:用户兴趣和热点信息瞬息万变。存储系统需要能够高效处理流式数据,支持实时或近实时的数据更新与索引。将『冷』数据(历史存档)与『热』数据(实时反馈)分层存储,并建立顺畅的数据升降级通道,确保推荐系统能够敏捷响应用户的最新意图和外界变化。
二、 存储之基:架构、效率与治理的支撑
数据处理的能力很大程度上受限于存储系统的架构。一个面向智能推荐优化的存储服务,是缓解信息过载的隐形基石。
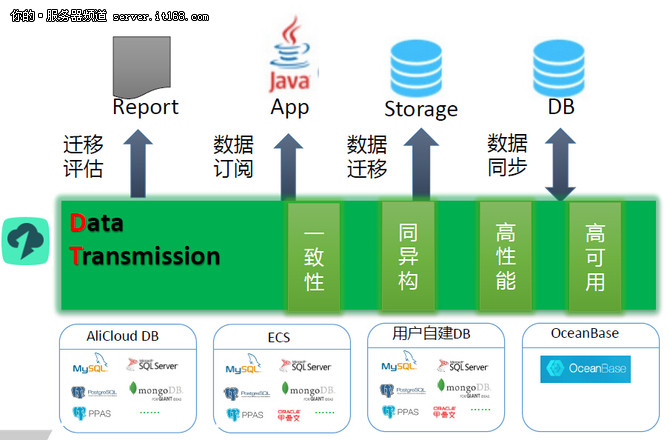
- 采用混合与分层存储架构:没有一种存储方案能适合所有数据类型。推荐系统需要结合使用多种存储技术:
- 高速缓存(如Redis, Memcached):用于存放热点用户画像、实时排名榜等对延迟极其敏感的数据。
- 在线分析处理数据库(如ClickHouse, Druid):用于快速聚合分析用户群体行为,支撑趋势发现和策略调整。
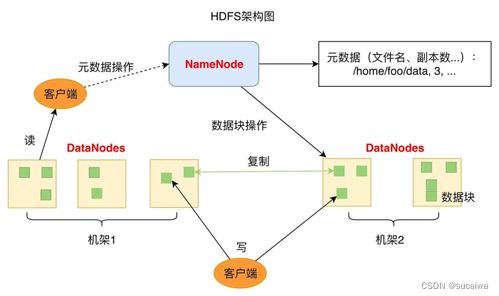
- 大数据存储(如HDFS, 对象存储):用于存放海量的原始日志、模型训练用的历史数据集。
- 向量数据库:随着Embedding技术的普及,专门为高维向量相似性搜索优化的存储,能极大提升内容匹配的效率与精度。
通过合理的分层,让数据在成本、性能和访问频率间取得最佳平衡。
- 优化数据存储与检索效率:信息过载对用户是负担,对系统则是性能挑战。存储层需要通过索引优化、数据压缩、列式存储等技术,实现毫秒级的数据检索,确保推荐引擎能快速处理复杂查询,在瞬间完成千万级候选物品的筛选与排序,避免因系统延迟而被迫采用更粗糙、更泛化的推荐策略。
- 强化数据生命周期与合规治理:并非所有数据都值得永久保存。明确的数据生命周期管理策略,能自动归档或清理过期、无效数据,降低存储成本与管理复杂度,同时也有助于提升查询效率。更重要的是,在存储层即嵌入隐私保护设计(如数据脱敏、匿名化),并确保所有数据操作符合法规要求(如GDPR、个人信息保护法),从源头上建立可信的推荐系统。
三、 服务之策:走向可解释与可控的推荐
当数据与存储层打下了坚实、灵活的基础,上层的推荐服务才能更游刃有余地解决信息过载问题。
- 支持可解释的推荐:将数据层存储的丰富特征与模型决策过程关联。当用户对推荐结果产生疑问时,系统能够追溯到是哪些数据特征(例如,“因为你昨天看了A,且很多喜欢A的人也看了B”)主导了本次推荐,这增加了系统的透明度,也让用户对自己的信息流向有更清晰的感知。
- 赋能用户控制权:在存储层面,可以专门维护用户主动设置的兴趣标签、屏蔽列表、探索偏好(如“拓宽推荐多样性”)等元数据。推荐算法在召回和排序阶段必须强制尊重这些用户显式指令,让用户从被动的接收者变为主动的参与者,从而个性化地管理自己的信息流负载。
- 实现动态探索与利用的平衡:依赖存储层提供的实时反馈数据流,推荐系统可以更精准地评估用户的兴趣边界,动态调整探索(推荐新内容)与利用(推荐已知感兴趣内容)的比例。当系统检测到用户信息摄入趋于单一或疲劳时,自动从更广泛的数据池中选取高质量、多样化的内容进行试探,智能地打破过载与茧房的恶性循环。
###
解决智能推荐时代的信息过载,是一场需要纵深配合的系统工程。仅仅在算法层面调参优化,如同在湍急的河流下游筑坝,效果有限且易反复。唯有深入上游,从数据和存储这一源头活水入手,通过提升数据质量、丰富数据维度、构建敏捷高效的存储服务体系,才能为推荐系统注入更强大的理解力、控制力和解释力,最终化『过载』为『适配』,让技术真正服务于人的信息福祉,而非让人迷失于信息的海洋。
如若转载,请注明出处:http://www.lookmq.com/product/65.html
更新时间:2026-06-19 22:51:38