58同城智能推荐系统的演进与实践 数据处理与存储服务的核心角色
在58同城智能推荐系统的发展过程中,数据处理和存储服务始终扮演着至关重要的角色。随着业务规模的不断扩大和用户需求的日益复杂,推荐系统经历了从简单规则驱动到深度融合机器学习的演进,而数据处理和存储服务始终是其稳定运行和持续优化的基石。
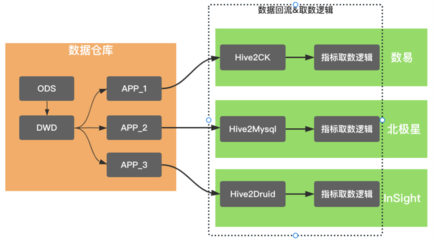
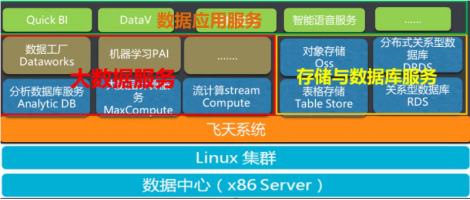
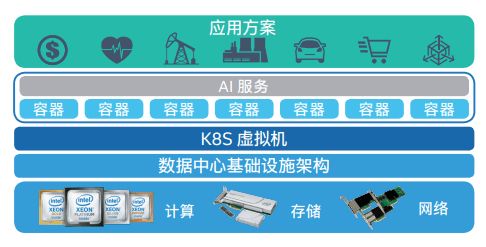
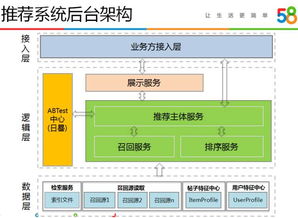
推荐系统的演进大致可以分为三个阶段:初期基于简单规则和统计的方法、中期引入协同过滤和内容推荐技术,以及当前基于深度学习和多源数据融合的智能推荐。在每个阶段,数据处理和存储服务都提供了关键支持。初期阶段,系统主要依赖关系型数据库存储用户和物品的基础数据;中期阶段,随着数据量的激增,系统引入了分布式存储和计算框架,如Hadoop和Spark,以处理海量用户行为数据;当前阶段,系统进一步优化为实时数据处理与离线批量处理相结合的架构,利用NoSQL数据库和消息队列技术实现低延迟、高并发的数据服务。
在实践中,58同城智能推荐系统的数据处理和存储服务注重以下核心要素:数据采集与清洗环节确保数据质量,通过ETL流程将多源异构数据转化为统一格式;存储服务采用分层设计,包括冷热数据分离和分布式存储策略,以提高查询效率并降低成本;系统通过数据监控和容灾机制保障服务的稳定性和可扩展性。例如,利用Kafka实现实时数据流处理,结合HBase和Redis存储用户画像和物品特征,显著提升了推荐的准确性和实时性。
数据处理和存储服务在58同城智能推荐系统的演进中不断优化,从基础的数据管理扩展到支持实时计算和智能决策,为系统的高效运行和用户体验的提升奠定了坚实基础。未来,随着人工智能技术的进一步发展,数据处理和存储服务将继续在推荐系统中发挥核心作用。
如若转载,请注明出处:http://www.lookmq.com/product/24.html
更新时间:2025-11-29 03:54:10